|
1 | | -~ todo |
| 1 | +# 链表:想写好链表代码可真要下点功夫 |
| 2 | + |
| 3 | +## 前言 |
| 4 | + |
| 5 | +上一篇文章我们探讨了数组这个非常基础的数据结构。对于数组,我们知道了数组在内存中是按照顺序存储并线性排列,所以具有“随机访问"的能力,但是对于删除和插入等操作却十分低效。 |
| 6 | + |
| 7 | +今天我们一起探讨一个新的数据结构—**链表**,看看链表是什么?学习链表有什么用? |
| 8 | + |
| 9 | +## 链表是什么 |
| 10 | + |
| 11 | +链表是一种非常重要的数据结构,应用的非常广泛,在写链表代码非常容易出错,所以面试中链表经常会被用来考察面试者的逻辑是否严谨。 |
| 12 | + |
| 13 | +链表它不像数组,数组需要的是一块连续的内存空间来存储,而链表并不需要一块连续的内存你空间(也就是可连续也可不连续),它可以利用“**指针**”(`next`域)将一组零散的内存块串联起来,所有链表的存储方式是随机存储。我们看看链表中的单个节点长什么样,如下如所示: |
| 14 | + |
| 15 | +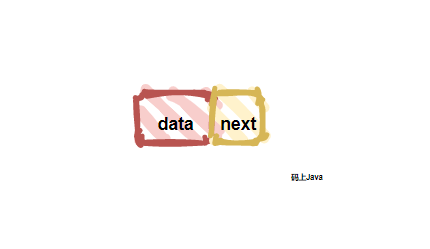 |
| 16 | + |
| 17 | +图中你可以看到,`data`和`next`。 解释一下: |
| 18 | + |
| 19 | +1. **data**: 存放结点值的数据域 ; |
| 20 | +2. **next**: 记录下个结点地址的指针,也叫做后继指针域; |
| 21 | + |
| 22 | +链表之所以能够将零散的内存块串联起来,主要就是依靠这个`next`指针。 |
| 23 | + |
| 24 | +那么接下来,今天我们一起了解三种最常见的链表结构,分别是**单链表**、**双向链表**、**循环链表**等。 |
| 25 | + |
| 26 | +### 1. 单链表 |
| 27 | + |
| 28 | +我们先来看看单链表的结构,如下图所示: |
| 29 | + |
| 30 | + |
| 31 | + |
| 32 | +图中我们可以发现,在单链表中每个单节点都包含两部分,也就是上面我们说的`data`和`next`。这里就不再解释了。除此之外,还有一个`head`,这个是什么呢? 这个其实是**头结点**,也就是链表的第一个节点。同样道理,链表最后一个结点我们称为**尾结点**,尾结点比较特殊,它的next指针是指向null的,也就是表示链表的最后一个结点。 |
| 33 | + |
| 34 | +### 2. 双向链表 |
| 35 | + |
| 36 | +我们先再来看看双向链表的结构,如下图所示: |
| 37 | + |
| 38 | + |
| 39 | + |
| 40 | +图中我们可以发现,双向链表是比单链表稍微复杂一些的,在单链表中只有一个方向,每个结点只有一个后继指针`next` , 而双向链表支持两个方向,每个结点中不仅有一个后继指针`next`,还有一个前继指针`pre`,而且第一个结点的前继指针`pre`是指向`null`的。 |
| 41 | + |
| 42 | +> 思考:双向链表每个结点使用两个指针有什么优缺点呢? |
| 43 | +
|
| 44 | +由图可知,单链表只支持一个方向的遍历,而双向链表是支持两个方向的遍历的。优点就是双向链表要比单链表灵活的多,但是这种灵活是要付出代价的。缺点就是如果存储相同数量的元素,相比单链表而言,双向链表的两个指针是比较浪费空间的。 |
| 45 | + |
| 46 | +### 3. 循环链表 |
| 47 | + |
| 48 | +提到循环链表,可分为单向循环链表和双向循环链表,其实都是由上述的两种链表演化而来。如下图所示: |
| 49 | + |
| 50 | +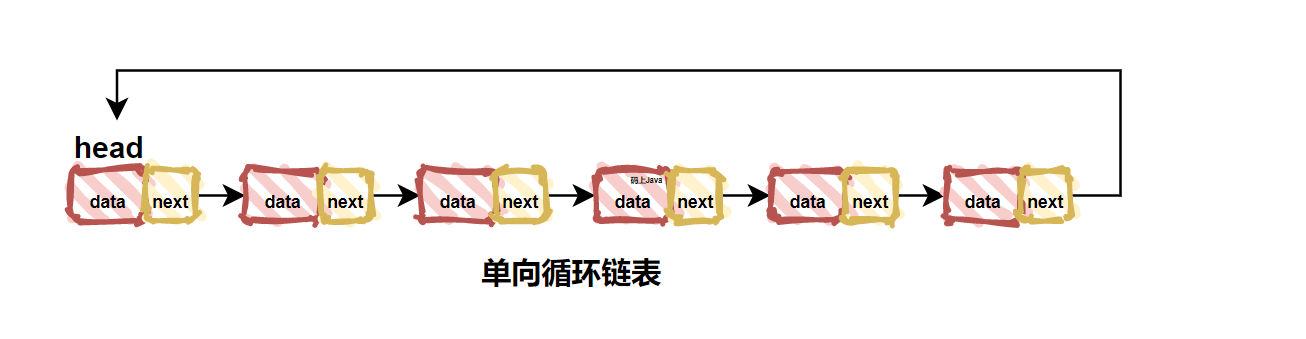 |
| 51 | + |
| 52 | +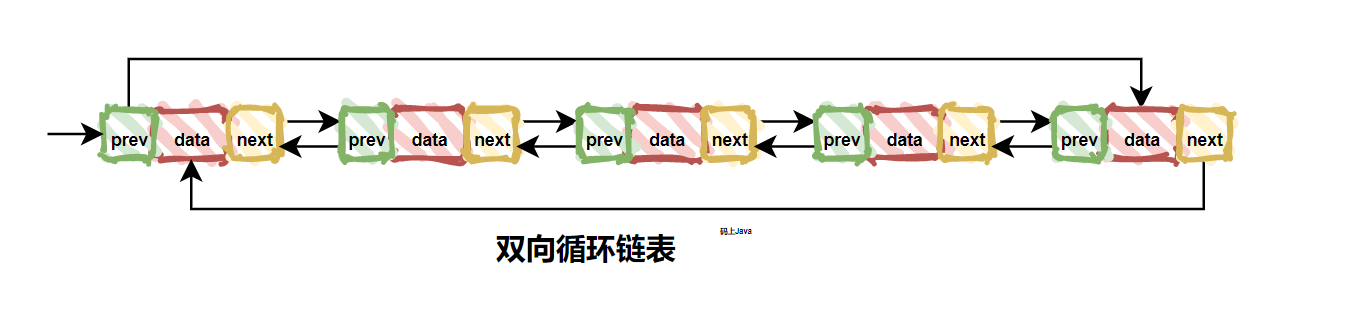 |
| 53 | + |
| 54 | +单链表的尾结点后继指针是指向`null`,而循环链表的尾结点后继指针是指向链表的头结点的,图中我们可以发现,循环链表就像一个环一样首尾连接。 |
| 55 | + |
| 56 | +## 链表的基本操作 |
| 57 | + |
| 58 | +上文中我们一起简单聊了几种常见的链表结构,下面我们以单链表为例,用图解的方式看看链表是怎么进行增删改查的,在开始之前我们先创建一个类。代码如下: |
| 59 | + |
| 60 | +```java |
| 61 | +public class MyLinked { |
| 62 | + |
| 63 | + private Node head; |
| 64 | + |
| 65 | + private Node last; |
| 66 | + |
| 67 | + private int size; |
| 68 | + |
| 69 | + private static class Node{ |
| 70 | + |
| 71 | + public int data; |
| 72 | + |
| 73 | + public Node next; |
| 74 | + |
| 75 | + public Node(int data){ |
| 76 | + this.data=data; |
| 77 | + } |
| 78 | + } |
| 79 | + |
| 80 | +} |
| 81 | +``` |
| 82 | + |
| 83 | +### 1. 查找结点 |
| 84 | + |
| 85 | +当数组在查找元素的时候,可以通过下标快速定位到对应元素。但是链表可没这个能力,在链表中查找某个元素,只能从头结点开始一个个向后查找,直到找到要查找的元素或者找不到。由于从头开始遍历,故时间复杂度为O(N)。链表查找结点过程如下图所示: |
| 86 | + |
| 87 | +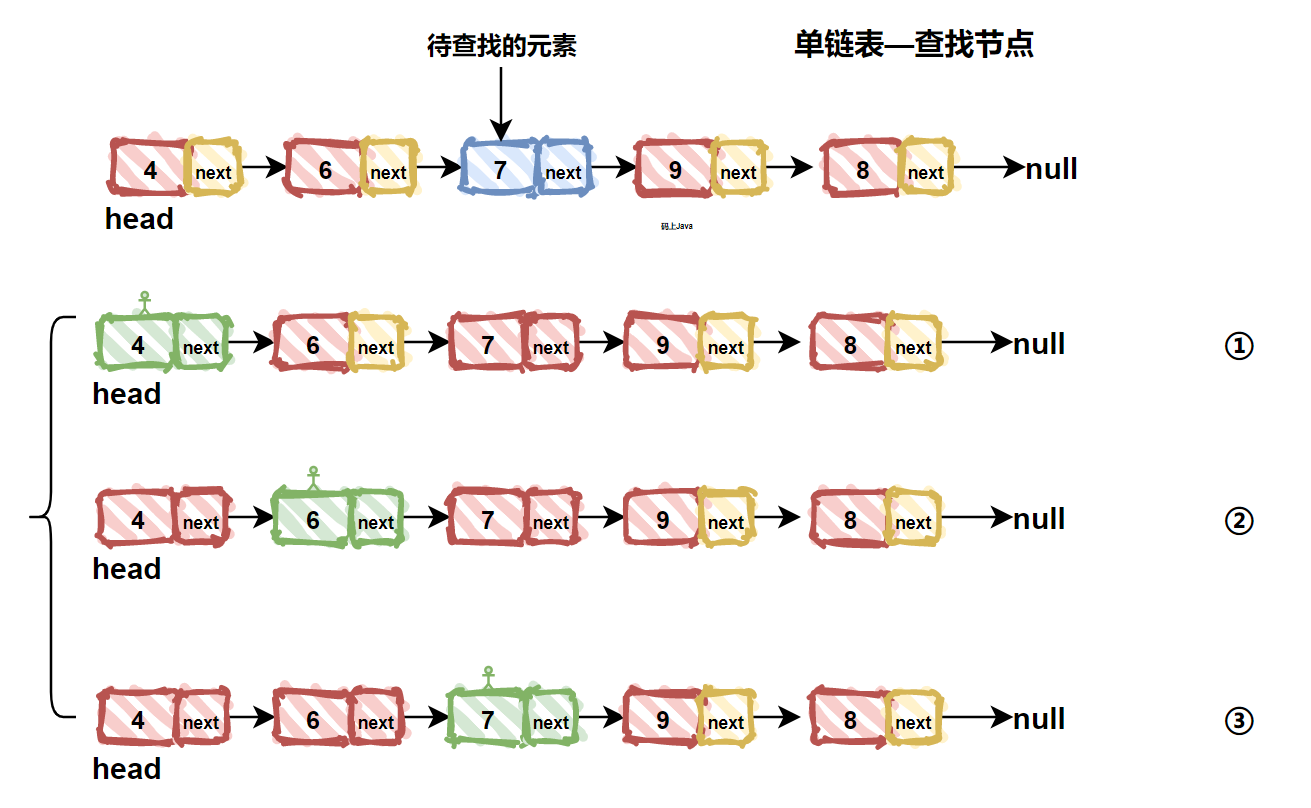 |
| 88 | + |
| 89 | + 查找指定结点的代码如下: |
| 90 | + |
| 91 | +```java |
| 92 | +/** |
| 93 | + * 获取指定位置的元素 |
| 94 | + * |
| 95 | + * @param index 指定位置 |
| 96 | + * @return |
| 97 | + * @throws Exception |
| 98 | + */ |
| 99 | +public Node find(int index) throws Exception { |
| 100 | + if (index < 0 || index > size) { |
| 101 | + throw new IndexOutOfBoundsException("超出链表实际节点范围!"); |
| 102 | + } |
| 103 | + Node temp = head; |
| 104 | + for (int i = 0; i < index; i++) { |
| 105 | + temp = temp.next; |
| 106 | + } |
| 107 | + return temp; |
| 108 | +} |
| 109 | +``` |
| 110 | + |
| 111 | +### 2. 更新结点 |
| 112 | + |
| 113 | +链表中更新结点如查找过程类似,也是从头开始遍历,找到要更新的结点那个位置,然后直接赋值就可以了。链表更新结点过程如下图所示: |
| 114 | + |
| 115 | +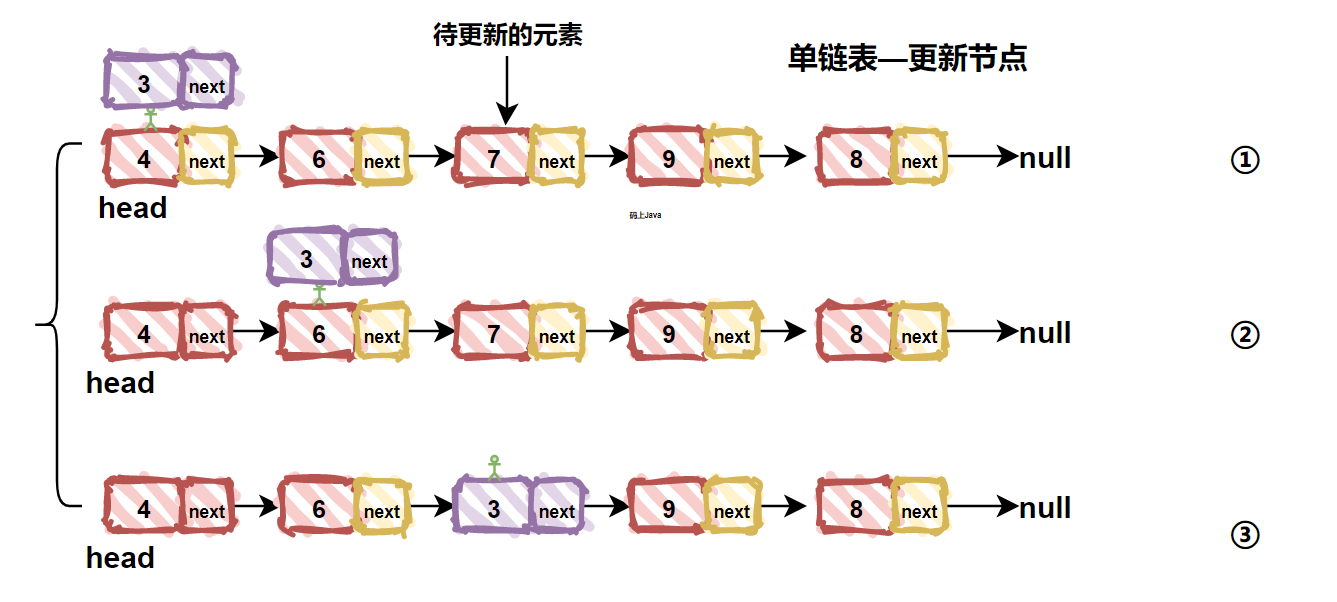 |
| 116 | + |
| 117 | +### 3. 新增结点 |
| 118 | + |
| 119 | +链表中新增结点需要考虑三种情况,分别是:头部新增、中间新增、尾部新增。 |
| 120 | + |
| 121 | +我们先来看看最简单的尾部新增的情况,只需要遍历链表,如果当前结点的`next`指向`null `的话,就直接该结点的`next`指针指向新增的这个结点就可以了。如下图所示: |
| 122 | + |
| 123 | +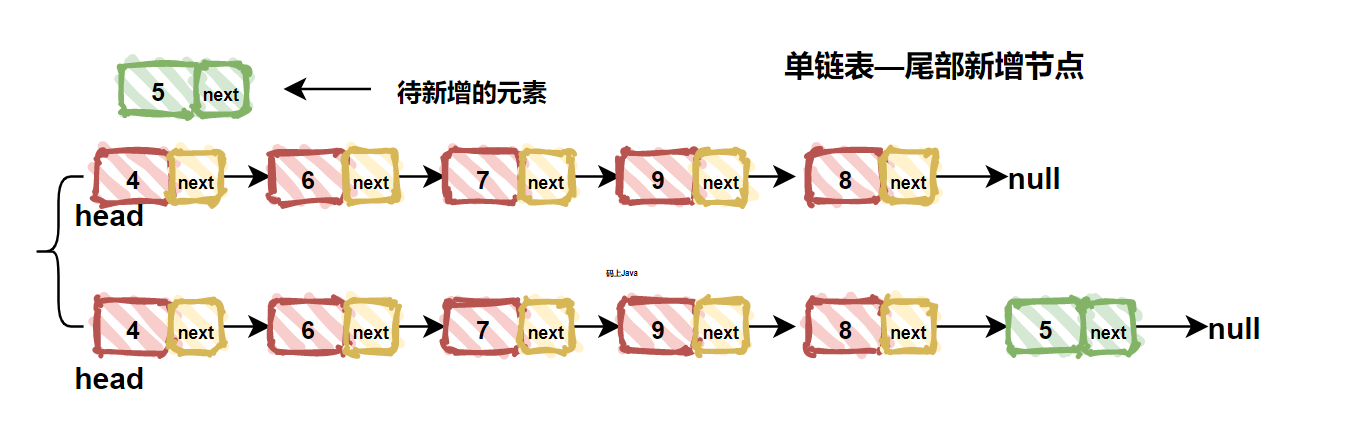接下来我们在看看头部插入情况,因为在链表头部插入,所有我们不需要遍历链表。我们先将新增的这个结点的`next`指针指向原链表的头结点`head`,然后修改一下头结点的位置为新增的这个结点即可。如下图所示: |
| 124 | + |
| 125 | +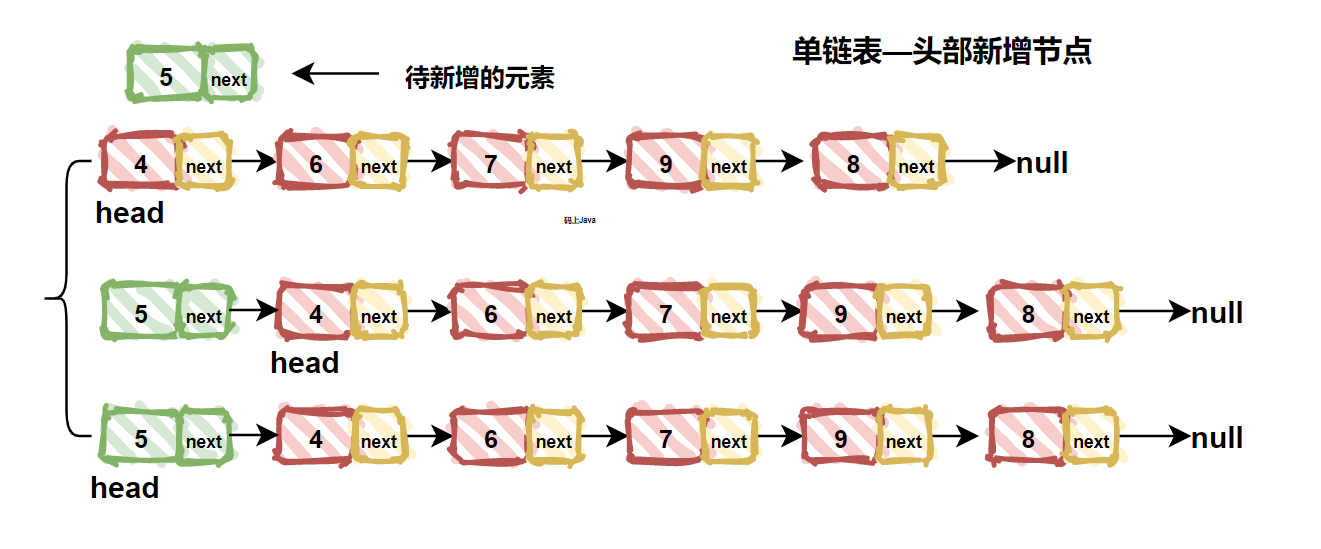 |
| 126 | + |
| 127 | +最后我们再看看中间新增结点的情况,此时我们需要遍历链表,第一步:将新增的结点的`next`指针指向新增的位置的结点,第二步:将新增的这个位置的前置结点的`next`指针指向新结点即可。这个过程一点要注意,一点不能颠倒顺序,否则容易链表的断开。如下图所示: |
| 128 | + |
| 129 | +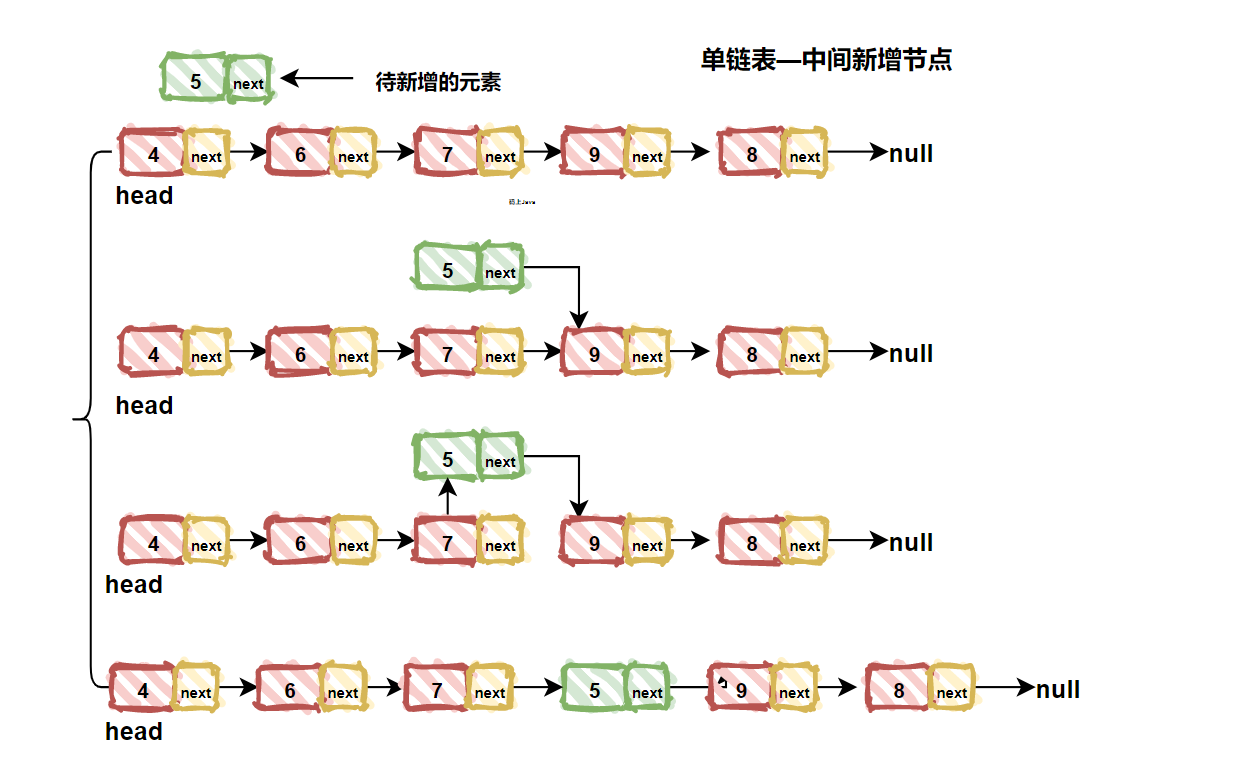 |
| 130 | + |
| 131 | +指定位置新增结点的代码如下: |
| 132 | + |
| 133 | +```java |
| 134 | + /** |
| 135 | + * 指定位置新增元素 |
| 136 | + * |
| 137 | + * @param data |
| 138 | + * @param index |
| 139 | + * @throws Exception |
| 140 | + */ |
| 141 | +public void insert(int data, int index) throws Exception { |
| 142 | + if (index < 0 || index > size) { |
| 143 | + throw new IndexOutOfBoundsException("超出链表实际节点范围!"); |
| 144 | + } |
| 145 | + Node insertNode = new Node(data); |
| 146 | + if (size == 0) { |
| 147 | + // 空链表 新增 |
| 148 | + head = insertNode; |
| 149 | + last = insertNode; |
| 150 | + } else if (index == 0) { |
| 151 | + // 头部新增 |
| 152 | + insertNode.next = head; |
| 153 | + head = insertNode; |
| 154 | + } else if (size == index) { |
| 155 | + // 尾部新增 |
| 156 | + last.next = insertNode; |
| 157 | + last = insertNode; |
| 158 | + } else { |
| 159 | + // 获得 新增的位置前面一个元素 |
| 160 | + Node preNode = find(index - 1); |
| 161 | + insertNode.next = preNode.next; |
| 162 | + preNode.next = insertNode; |
| 163 | + } |
| 164 | + // 链表实际长度+1 |
| 165 | + size++; |
| 166 | +} |
| 167 | +``` |
| 168 | + |
| 169 | + |
| 170 | + |
| 171 | +### 4. 删除结点 |
| 172 | + |
| 173 | +链表中删除结点同样需要考虑三种情况,分别是:头部删除、中间删除、尾部删除。 |
| 174 | + |
| 175 | +我们先来看看最简单的尾部删除的情况,当遍历到链表倒数第二个结点的结点,直接将该结点的`next`结点指向`null`即可。如下图所示: |
| 176 | + |
| 177 | +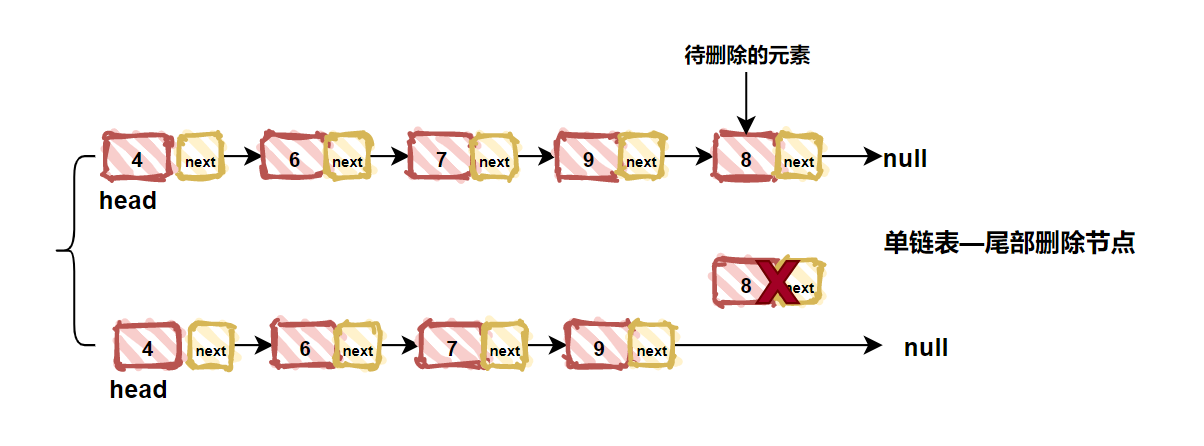 |
| 178 | + |
| 179 | +接下来我们在看看头部删除情况,当删除链表头部结点的时候,只需要将头结点变更为原头结点的下一个结点为新的头结点即可。如下图所示: |
| 180 | + |
| 181 | +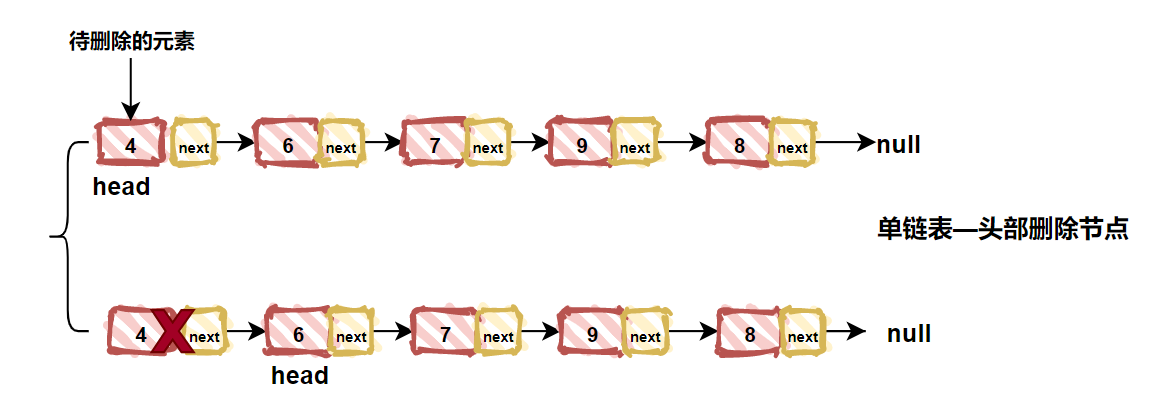 |
| 182 | + |
| 183 | +最后我们再看看中间删除结点的情况,这个情况的关键是找到待删除结点的前置结点。修改这个前置结点的下一个结点为待删除结点的下一个结点接口。如下图所示: |
| 184 | + |
| 185 | +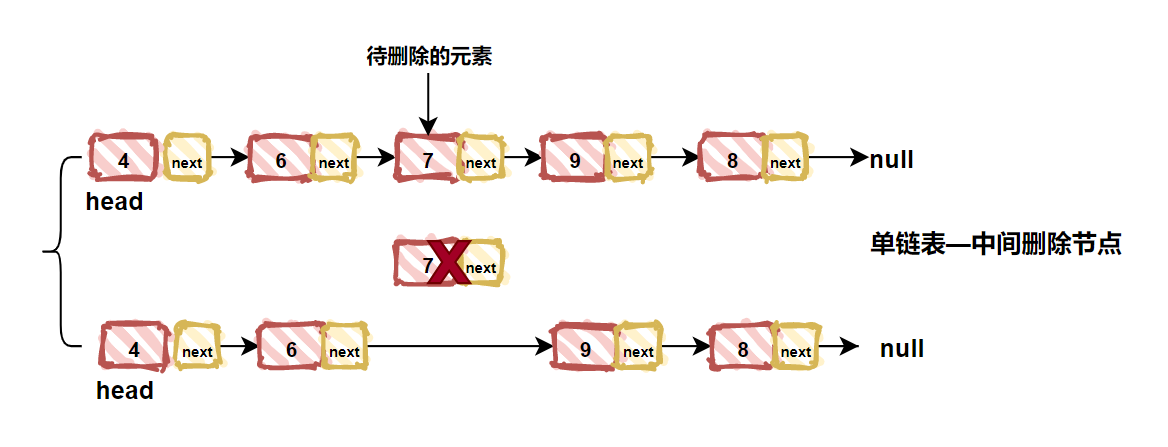 |
| 186 | + |
| 187 | +指定位置新增结点的代码如下: |
| 188 | + |
| 189 | +```java |
| 190 | +/** |
| 191 | + * 删除指定位置的链表元素 |
| 192 | + * |
| 193 | + * @param index 指定位置 |
| 194 | + * @return 删除的元素 |
| 195 | + * @throws Exception |
| 196 | +*/ |
| 197 | +public Node delete(int index) throws Exception { |
| 198 | + if (index < 0 || index > size) { |
| 199 | + throw new IndexOutOfBoundsException("超出链表实际节点范围!"); |
| 200 | + } |
| 201 | + Node removeNode = null; |
| 202 | + if (size == 0) { |
| 203 | + // 头部删除 |
| 204 | + removeNode = head; |
| 205 | + head = head.next; |
| 206 | + } else if (size - 1 == index) { |
| 207 | + // 尾部删除 |
| 208 | + // 获得 删除的位置前面一个元素 |
| 209 | + Node preNode = find(index - 1); |
| 210 | + removeNode = preNode.next; |
| 211 | + preNode.next = null; |
| 212 | + last = preNode; |
| 213 | + } else { |
| 214 | + // 中间删除 |
| 215 | + // 获得 删除的位置前面一个元素 |
| 216 | + Node preNode = find(index - 1); |
| 217 | + removeNode = preNode.next; |
| 218 | + preNode.next = preNode.next.next; |
| 219 | + } |
| 220 | + // 链表实际长度-1 |
| 221 | + size--; |
| 222 | + return removeNode; |
| 223 | +} |
| 224 | +``` |
| 225 | + |
| 226 | +## 总结 |
| 227 | + |
| 228 | +本文简单介绍了链表这个数据结构,我们知道了链表的优点是大小可变,插入和删除的效率很都非常高。缺点就是如果查找一个元素,你只能从头开始遍历,所以说查询的效率很低。 |
| 229 | + |
0 commit comments